Big Data is everywhere
The big data technologies are one of the currently most discussed topics in computer science and
information technology media. They are a possible answer to a recurring, and quickly expanding, issue and may represent a major paradigm shift in how a company
manages its data. The underlying concept deals with how one can manage and process data sets of very large and/or quickly increasing size where classical
methods may fail (or at the very least create performance or robustness issues). Nowadays, these issues are present in various fields, including life sciences,
financial analysis, physics, user/customer analysis, and general web-based data analysis. The exponential growth of associated data may require new storage and
processing methods and even companies that are not at this stage yet may be confronted by similar issues in the near future.
Our in-depth knowledge of these big data issues and the associated
technologies allows us to support you in evaluating your needs and selecting adequate solutions for all possible axes of improvement.
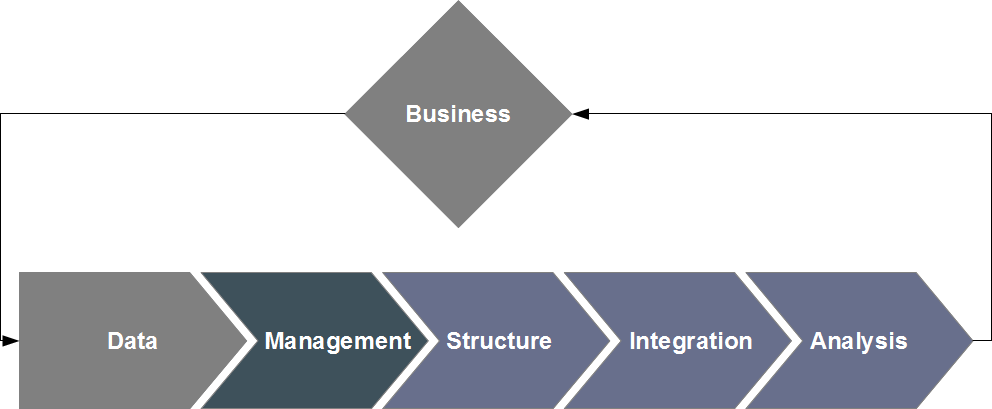
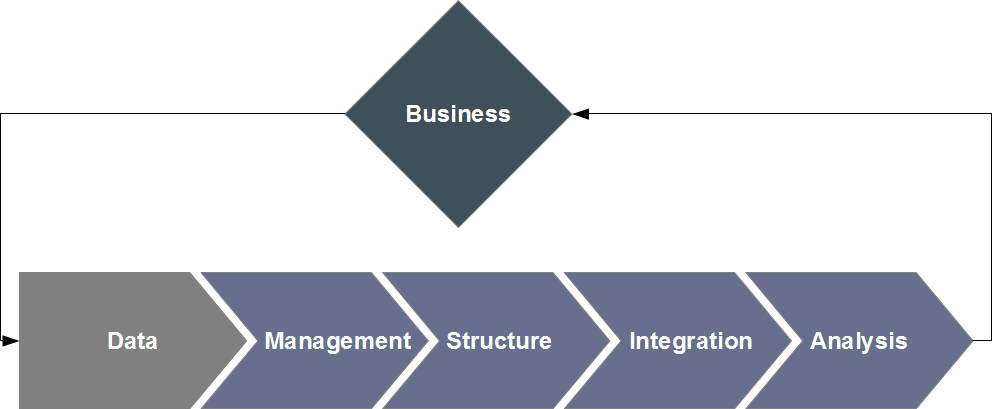
Process overview
Storage and processing: probably the most specific component of the big data issue. Distributed
file systems, virtual storage (cloud), specialized nosql databases, distributed computing... These are some of the many
components necessary to a complete solution for the efficient processing of large datasets, and most of them are specialized enough to warrant calling on
dedicated experts; these core technologies are needed for a full information processing platform, and will entail changes to both praxis (e.g. parallelizing your
analysis algorithms) and methodology (e.g. new algorithmic solutions, such as MapReduce).
Analysis: supervised or semi-supervised classification, clustering, statistical
learning, complex systems, anomaly detection or pattern recognition... While most analytical tools are not specific to big data,
the sheer quantity of managed data may turn analysis into a mandatory processing step, and adequacy of strategy and techniques can become a critical step in optimally
valorizing your data.
Curation: automated processing, information structuration, natural language
processing... This oft-neglected facet can quickly become a bottleneck when manual curation of your data cannot be achieved because of their large size.
Integration: ideally backed by a robust knowledge management system, integration of heterogeneous data is a necessary step if you wish to achieve
interoperability of your systems and efficient information sharing.
Knowledge modeling and management
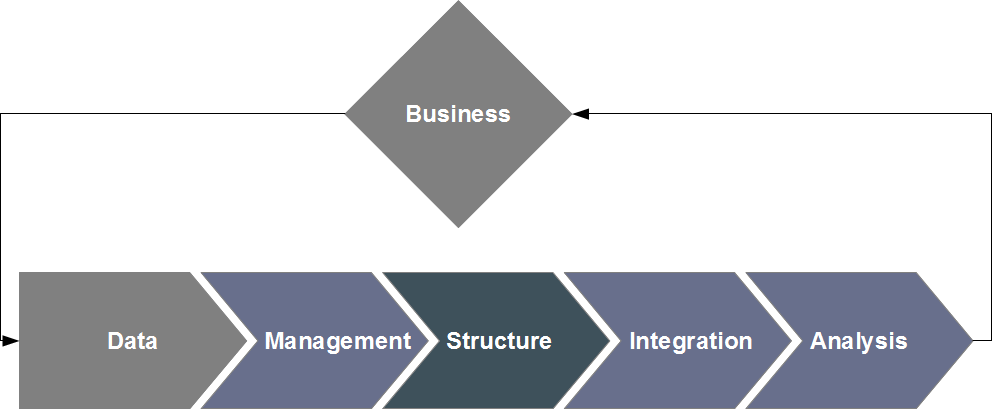
Knowledge management is a catch-all term for all methods and techniques concerned with organizing, processing, sharing and presenting the
collective knowledge of your company, whether it was internally produced or generated by a third party.
In essence, introducing knowledge management into your praxis allows for the valorization of your implicit knowledge by making it accessible and understandable
to all. Its codification (along with the use of appropriate support solutions) enables your structure to systematize its use, extend it, and possibly leverage
it as a new source of added value, because it can now be dealt with as a full-fledged data source and be therefore be processed along with other sources by
the appropriate tools.
Our expertise of knowledge management and its integration to pre-existing information systems will
allow us to accompany you in the modeling of your knowledge and its applications.
Implementation guidelines
In practice, knowledge management is at the confluence of several interacting and collaborating fields of expertise:
- Human resources (your teams) will be the first producers of both knowledge and its modeling. Organized into praxis or
focus groups, they will formulate the first definitions of key concepts and how they relate to your business and data.
- Knowledge structuring will be supported and expanded through the construction or usage of ontologies
(formal representation of concepts and their relationships) dedicated to your field.
- Knowledge leveraging will be achieved with dedicated information systems that, with the probable help of specialized components
(e.g. language processing), will create and store relationships between concepts and data, by way of annotation (manual or automated).
- Accumulated knowledge will generate added value with the adjunction of data analysis tools that will be able to computationally process this knowledge-as-data
and discover patterns or anomalies that were, until then, undetectable.
Data Integration primer
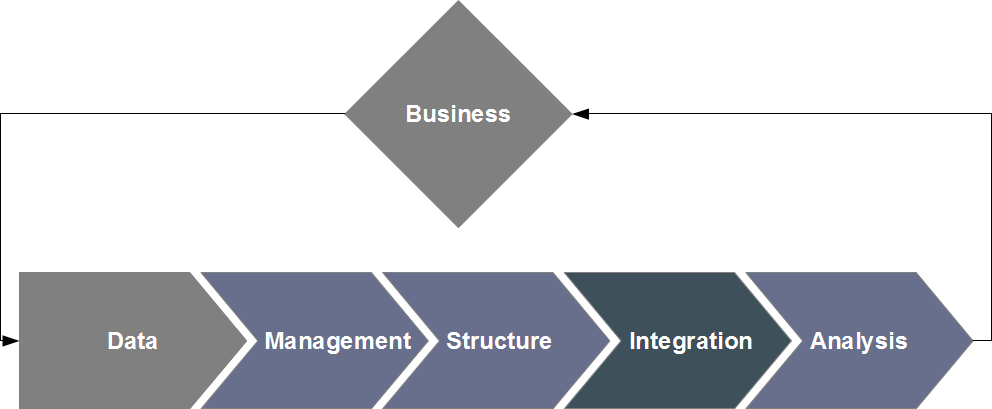
Data integration is the process of combining multiple information sources into an internally consistent unified whole in order to offer
a unique, aggregated access to the user. The need for such a processing step grows with the complexity, heterogenity and volume of data, as well as the
number of data providers (which may include external sources).
Our command of heterogeneous data integration allows us to oversee all steps of the implementation
of a complete solution, while taking into accound the specifics of your field and your practices.
Integration process
The implementation of a data integration solution will have to offer answers to a number of questions, depending on your environment:
- Modeling: a preliminary step will consist in the joint modeling of all your data, so as to define which pre-existing
"bridges" are available to ensure they are properly aggregated together.
- Integration strategy: depending on both data complexity and data provider accessibility (e.g. internal vs.
external source), light coupling, real-time methods based on sources acting as virtual providers (e.g. via web services) may be substituted to the
more traditional "warehouse" strategies ("ETL": Extract - Transform - Load)
- Delivery: depending on intended use, dedicated front-end tools for data access and visualization or interaction
networks powering interoperability between existing software will be preferred.
- Semantic support: all aforementioned phases will strongly benefit from
knowledge management and the modeling of key concepts. This approach
can indeed help unambiguously structure data used for integration. This is actually the underlying concept of the semantic web.
General uses for data analysis
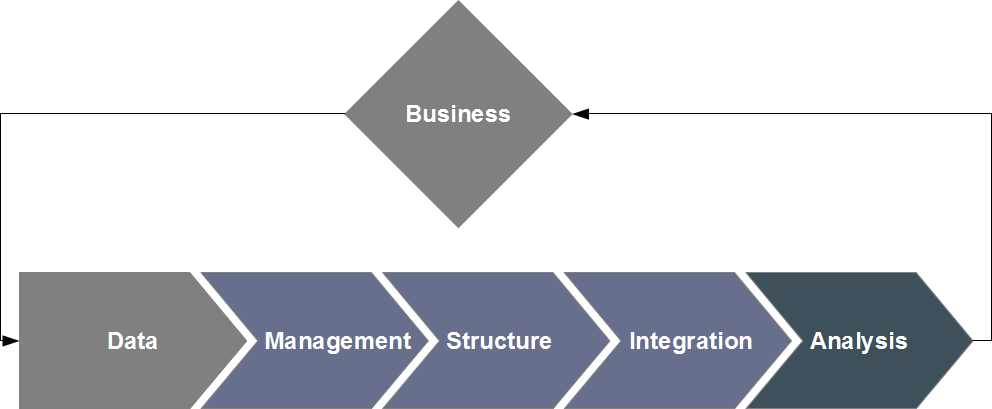
Data analysis consists in applying mathematical, statistical and algorithmic tools to data of interest so as to uncover new information and
create value: discovery of novel knowledge, validation or invalidation of hypothesis, decision-making support, parameter optimization...
Our extended practice of data analysis allows us to adapt a wide range of analytical tools to your
functional field and needs and help your extract new value from your data.
A few examples
Questions that can theoretically be answered with these techniques are innumerables. A few examples that Sycomor has worked on in the
past follow:
- supervised or semi-supervised classification for disseminating knowledge from a small subset of annotated data to a larger dataset;
- clustering of data to help uncover similarity classes;
- parameter optimization for the improvement of a production process;
- search for explicative or approximating models in data prediction (e.g. time series prediction);
- agent-based modeling and simulation for scenario analysis and hypothesis generation;
- etc.
Ideally, data analysis should be integrated into a complete processing pipeline (upstream
data integration,
knowledge modeling; downstream information management system and
visualization tools). Without minimizing a potentially high computation cost (some questions might not be solved in real time and might need access to computing clusters, whether
real or virtual), data analysis is a powerful tool that can be successfully applied to a wide variety of problems and yield significant qualitative or quantitative gains for
your business.
A functional domain example: Life Sciences
Life sciences are, as a whole, a very complex and multi-faceted field: they explore wide-ranging problematics (from exploratory biology to
therapeutic praxis, from understanding live organisms and their inner workings to treating a pathology, encompass a large variety of interacting approaches and fields
of expertise, process rich data (that are also heterogeneous, highly dimensional, and usually in large quantities). For all these reasons, a rational, structuring
and systematic approach is the only option when implementing data computational processing; the many available software solutions for analysis, information management
and biological knowledge modeling are a clear marker of this need.
Sycomor boasts a long experience in delivering software solutions for life sciences projects. In addition to
our aforementioned general expertise, we also offer you our understanding of the life sciences field, its language and its codes. We can thus offer our support on
the whole extent of your issues and help you in your decision-making process when looking for robust solutions to your information management needs.
A few examples of our realizations
- Design, management and implementation of industrial information systems;
- Design and implementation of innovative heterogeneous data analysis tools (genomics, proteomics, phenomics, etc.);
- Design and implementation of heterogeneous data integration structures (clinical data, genomics, proteomics, phenomics, etc.)
- Design and implementation of structured annotation software, based on language processing and ontology-based knowledge
management;
- Design of a big data-oriented software superstructure.